REX | Airflow
Contenu
Contenu
Apache Airflow est un outil de planification de workflows open source qui permet de définir, planifier et suivre les tâches et les workflows de manière centralisée. Il est largement utilisé dans l’industrie pour automatiser les processus de traitement de données, tels que l’extraction, la transformation et le chargement de données (ETL), l’analyse de données en temps réel et la gestion de pipelines de machine learning.
Airflow utilise un concept de DAG (Directed Acyclic Graph) pour représenter les workflows de tâches. Un DAG est un graphe orienté qui ne contient pas de cycles. Chaque nœud du graphe représente une tâche à exécuter, tandis que les flèches représentent les dépendances entre les tâches. Airflow exécute les tâches de manière séquentielle en suivant les dépendances définies dans le DAG.
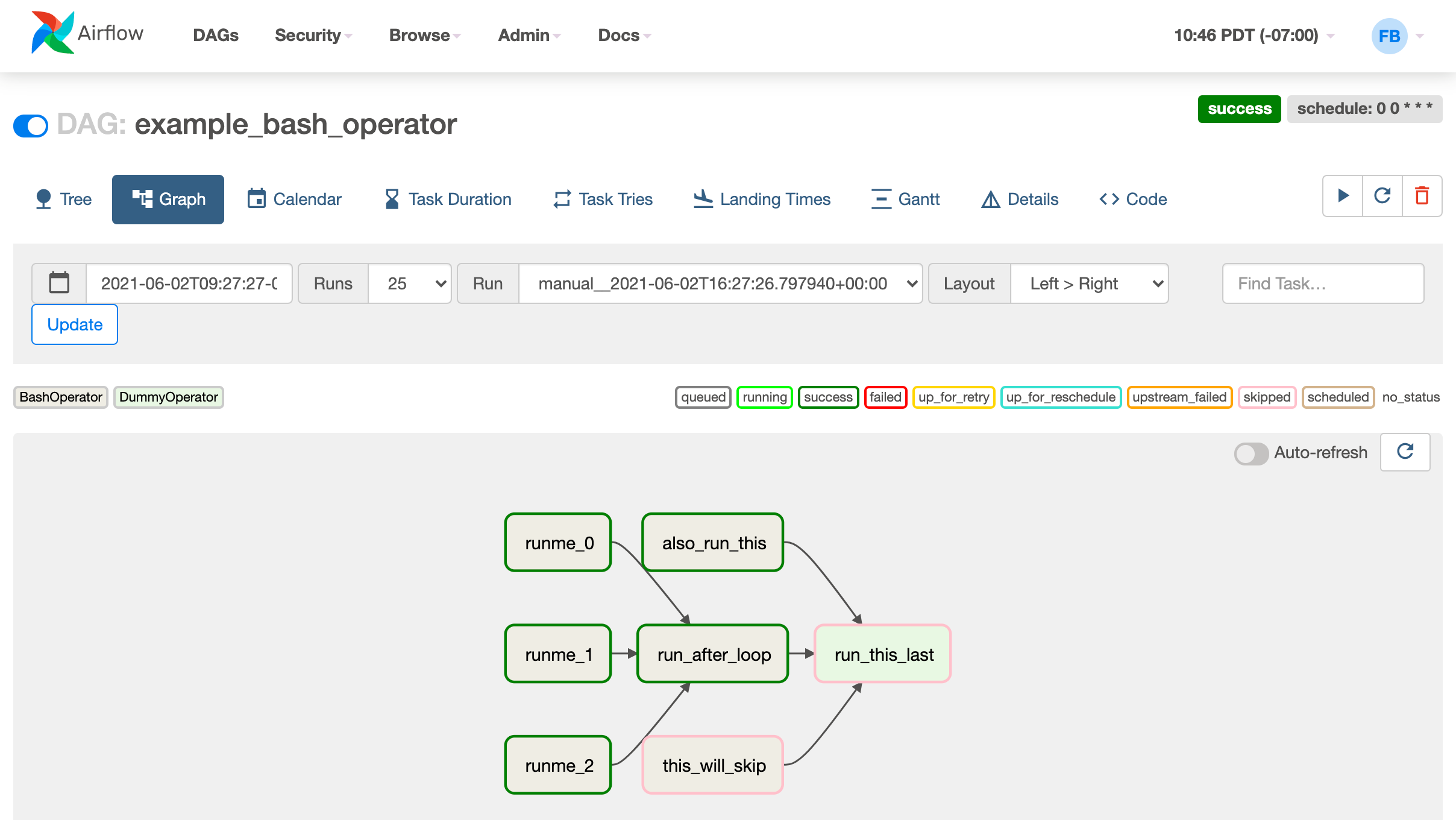
DAG
Airflow offre une interface utilisateur web pour définir et suivre les workflows, ainsi qu’un moteur de travail qui exécute les tâches sur des instances dédiées ou des conteneurs. Il est également extensible grâce à un système de plugins qui permet d’ajouter de nouvelles fonctionnalités et de s’intégrer à d’autres outils et services.
Dashboard
Comment déployer un serveur Airflow ?
Voici quelques façons courantes de déployer un serveur Airflow :
Déploiement local
Vous pouvez déployer un serveur Airflow sur votre ordinateur local en installant Airflow sur votre système d’exploitation et en exécutant le serveur web et le moteur de travail sur votre machine. Cette approche est généralement utilisée pour le développement et les tests.
Déploiement sur un serveur physique ou virtuel
vous pouvez déployer un serveur Airflow sur un serveur physique ou virtuel en installant Airflow sur l’OS du serveur et en exécutant le serveur web et le moteur de travail sur ce dernier. Cette approche est généralement utilisée pour les petits déploiements ou pour les déploiements de tests.
Déploiement sur un cloud public :
Vous pouvez déployer un serveur Airflow sur un cloud public, comme Amazon Web Services (AWS), Google Cloud Platform (GCP) ou Microsoft Azure. Vous pouvez utiliser une instance dédiée ou une instance dédiée en utilisant un conteneur, comme Docker. Cette approche est généralement utilisée pour les déploiements de production de grande taille.
- Amazon Web Services (AWS): AWS propose plusieurs services pour exécuter Airflow, tels que EC2 (instances dédiées), ECS (conteneurs) et EKS (Kubernetes).
- Google Cloud Platform (GCP): GCP propose également plusieurs services pour exécuter Airflow, tels que Compute Engine (instances dédiées), Container Engine (conteneurs) et Kubernetes Engine (Kubernetes).
- Microsoft Azure: Azure propose également plusieurs services pour exécuter Airflow, tels que Virtual Machines (instances dédiées), Container Instances (conteneurs) et AKS (Kubernetes).
- Heroku: Heroku est un service de cloud PaaS (Platform as a Service) qui permet de déployer facilement des applications web, y compris Airflow.
Déploiement sur un service cloud dédié et managé :
- Google Cloud Composer: Google Cloud Composer est un service cloud de GCP qui permet de déployer et de gérer facilement des workflows basés sur Apache Airflow. Composer offre une interface utilisateur simple et une intégration native avec d’autres services de GCP, ce qui en fait une option attrayante pour les utilisateurs de GCP souhaitant utiliser Airflow.
- AWS Glue: AWS Glue est un service cloud d’AWS qui permet de développer, déployer et gérer facilement des workflows d’extraction, de transformation et de chargement de données (ETL). Glue utilise Apache Airflow comme moteur de workflow et offre une interface utilisateur simple et une intégration native avec d’autres services d’AWS.
- Astronomer: Astronomer est un service cloud qui permet de déployer et de gérer facilement des serveurs Airflow sur plusieurs cloud publics, tels que AWS et GCP. Astronomer offre une interface utilisateur simple et une intégration native avec d’autres services cloud, ce qui en fait une option attrayante pour les utilisateurs de plusieurs cloud publics souhaitant utiliser Airflow.
Exemple de DAG avec un opérateur Kubernetes ?
Ce DAG crée un pod Kubernetes qui exécute la commande echo Hello World et passe un secret Kubernetes en tant que variable d’environnement au pod.
Le DAG définit également une dépendance entre les tâches, de sorte que la tâche déclenche une autre tâche une fois qu’elle a été exécutée avec succès.
|
|
Il y a plusieurs choses à remarquer dans ce code :
La définition du DAG comprend des arguments par défaut tels que le propriétaire, la date de démarrage, le nombre de tentatives de reprise et le délai de reprise. Ces arguments sont utilisés pour contrôler le comportement du DAG.
Le pod Kubernetes est défini en utilisant la classe KubernetesPodOperator. Cette classe prend en charge de nombreux paramètres qui permettent de contrôler le comportement du pod, tels que l’image du conteneur, les commandes à exécuter et les secrets à passer au pod.
Les secrets Kubernetes sont définis en utilisant le paramètre secrets, qui est une liste de dictionnaires. Chaque dictionnaire décrit un secret et doit inclure un nom et un volume de secret. Le volume de secret est utilisé pour monter le secret dans le pod comme un fichier.
Les variables d’environnement sont définies en utilisant le paramètre env_vars, qui est une liste de dictionnaires.
Chaque dictionnaire décrit une variable d’environnement et doit inclure un nom et une valeur à utiliser pour initialiser la variable. Dans l’exemple ci-dessus, la valeur est obtenue à partir d’un secret Kubernetes en utilisant la clé value_from.
Les dépendances entre les tâches sont définies en utilisant les opérateurs de flux de travail » et «. Dans l’exemple ci-dessus, la tâche kubernetes_task lancera la tâche slack_task si elle n’échoue pas.
Conclusion
Apache Airflow est un outil de gestion de flux de travail open source populaire, mais il existe également de nombreuses alternatives qui peuvent être adaptées à différents besoins et contextes. Parmi ces alternatives, on peut citer Apache Oozie, AWS Step Functions, Luigi de Spotify et plus recemment Dagster.